See your stack clearly.
PlatformOwl helps companies track software tools, costs, access, and login information in one centralized platform.
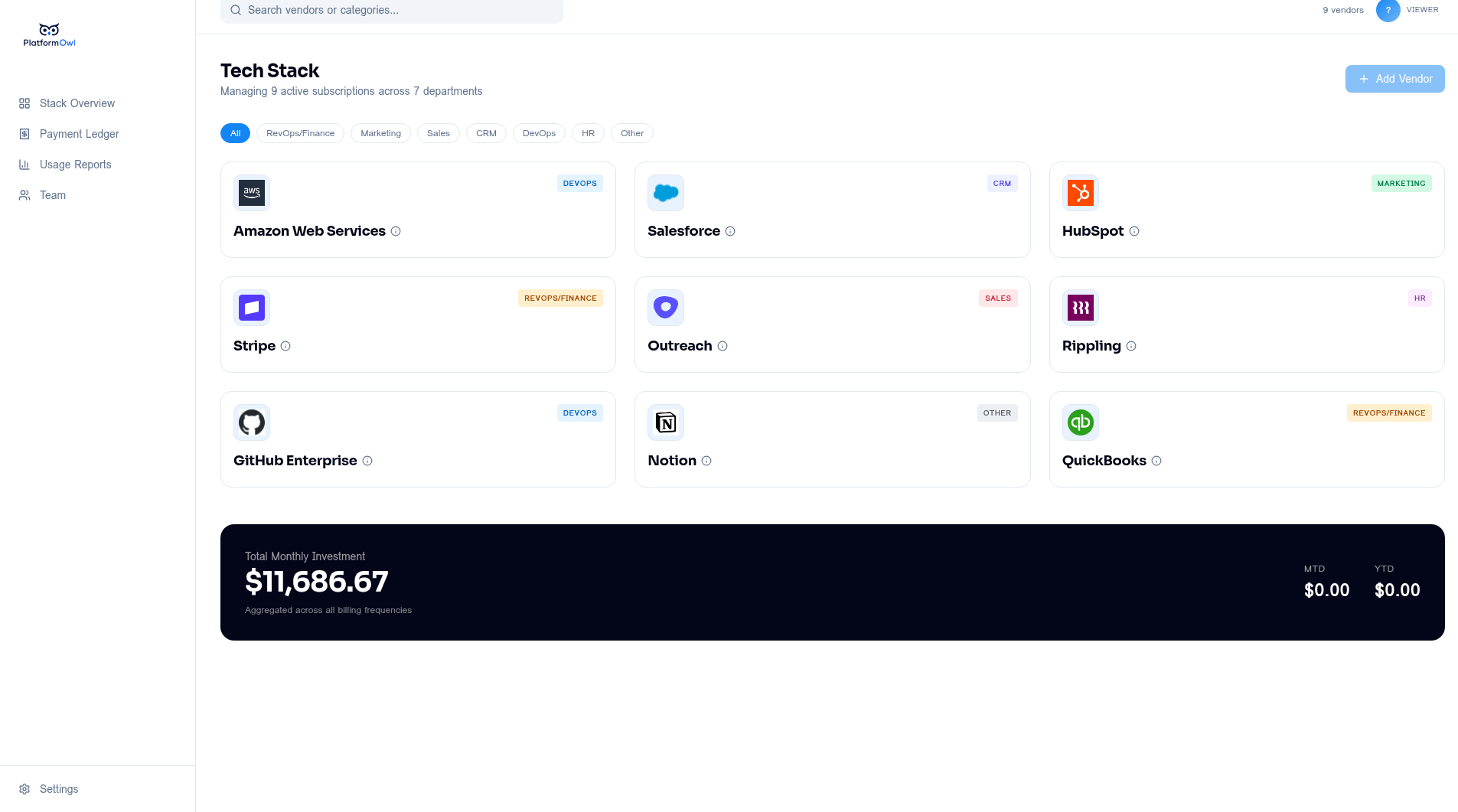
Track the tools your team already uses



















Features
Know what you use, who has access, and what it costs
Stop digging through invoices, password managers, and shared docs. PlatformOwl gives you a clean view of every tool your company uses — all in one place.
Every tool, one view
A single source of truth for every SaaS subscription, vendor, and internal platform your team relies on.
Costs you can see
Track monthly, quarterly, and annual spend normalized into one clear number — no more invoice archaeology.
Access without chaos
Securely store admin logins and ownership so the right people always know how to get in.
Payment ledger
A running history of every charge, per vendor, with filters and recurring templates for one-click logging.
Spend by category
See where your budget actually goes — DevOps, CRM, Marketing, HR — and spot redundancy fast.
Built for ops teams
Designed for the person who renews the contracts, owns the receipts, and answers the access questions.
Why PlatformOwl
The clarity ops teams have been missing.
Most companies don't have a tool problem — they have a visibility problem. PlatformOwl turns scattered spreadsheets and shared logins into one centralized record of truth.
- Centralize every vendor, login, and renewal date
- Normalize costs across monthly, quarterly, and annual billing
- Audit spend by category to cut redundant tools
- Hand off cleanly — never lose tribal knowledge again
Spend by category
MonthlyTestimonials
Loved by ops teams.
We went from a spreadsheet no one trusted to a single dashboard everyone checks. Renewals used to surprise us — now we see them coming.
Sarah Chen
VP of Operations, Finch Labs
I finally know who owns what login. Handing off vendor management when I went on leave was actually possible for the first time.
Marcus Okafor
Head of IT, Northwind Co
The payment ledger alone saved us hours every month. One click to log a recurring charge, and our finance team gets exactly what they need.
Elena Vasquez
Finance Lead, Atlas Growth
Pricing
Simple, transparent pricing for every stage of growth
Start for free and organize your company's software stack with clear visibility into tools, costs, access, and ownership.
Starter
- Up to 10 software tools
- 3 users
- Expense tracking
- Renewal reminders
- Simple dashboard
Growth
- Up to 50 software tools
- 10 users
- Expense tracking
- Renewal reminders
- Audit logs
- Notifications & reminders
- CSV export
Business
- Up to 100 software tools
- 50 users
- Expense tracking
- Renewal reminders
- Audit logs
- Notifications & reminders
- CSV export
- Advanced permissions
- Platform integrations
No contract. Cancel anytime.
FAQs
Questions? Answers.
Still have questions?
Send us a message and we will get back to you within 24 hours.
Get clarity on your stack today.
Open the dashboard and see every vendor, every login, and every dollar — in one place.